
神经网络
2017年07月18日 星期二, 发表于 北京
如果你对本文有任何的建议或者疑问, 可以在 这里给我提 Issues, 谢谢! :)
最近在使用github上的一个开源库DeepQA来对聊天语料进行训练,以使得机器人可以获得跟人对话的能力,从而摆脱对图灵的依赖,这个库用到了神经网络方面的知识,它是用了两个LSTM网络来组成encoder和decoder,来训练模型,主要思想应该是利用encoder来将问句转化为一个向量,然后再将该向量作为输出,输入到decoder,decoder输出即为回答,但具体怎么做还是要参考论文Sequence to Sequence Learning with Neural Networks,当然作为一个神经网络初学者,到这里,你可能想问LSTM又是什么,encoder和decoder又是干什么的,我当初也是这么迷茫,不要着急,咱们一步步地学,这一节我们就来学习最简单的神经网络模型。
神经网络
我们都知道人的大脑里有很多神经元,一个连着一个传递着大量的信息,而神经网络就是想要模拟人脑中的神经网络,来达到类似人脑一样学习的目的,那么,我们先来看最简单的一个神经网络长什么样。

神经网络通常有三层,输入层、隐藏层(隐藏层也可以有多层,这里最简单的情况只有一层隐藏层)、输出层,每一层上都有一些圆圈,这些圆圈就是我们的“神经元”,那么它的结构是怎样的呢?如下图:

每一个神经元,都会接受一些输入,然后经过一些计算后,再输出一个数据,那么我们需要搞清楚,这些输入数据怎么来,是怎么计算从而得出的输出。
首先是输入,对于输入层的神经元,他们没有接受输入的过程,每个神经元节点自己就是一个输入数据。而从隐藏层开始直到输出层,每一个神经元接受的输入实际上就是前面一层的各个神经元节点的输出,例如输入层有三个节点,那么对隐藏层的神经元来说,每个神经元接受的输入就是输入层的三个节点的值,例如x1、x2、x3,隐藏层假设有4个节点,这4个节点的输出便是输出层每个节点的输入。
知道了输入数据是什么,我们接下来要弄清楚怎么从输入得到输出,为了方便描述,我还是自己画图并计算吧。我们来看下图:

首先上一层的每一个神经元都会有一条线连接到下一层的每一个神经元,这条线上都有一个独特的权值(这也是需要我们最后学习获得的参数),那么一个神经元的输出的计算方式就是上一层的所有输入的一个加权求和,但是在图中我们可以看到多了一个输入是b,它其实也是一个需要学习获得的参数(可以当做一个特殊的神经元,不会接受上一层的输入来计算获得输出值,他输出的值就是它本身,是需要学习获得的),加权求和之后我们得到了y,然后再对y计算一个sigmoid函数,就得到了该神经元节点的输出了,看到这里,你是不是觉得有点似曾相识的感觉,这一个神经元的计算过程不就是逻辑回归的过程吗,一模一样啊!我们知道逻辑回归主要用来处理分类问题,而神经网络相当于将很多个逻辑回归的过程组合起来,组成了一个相当复杂的黑箱,你只要告诉它输入,输出,他就能学习到输入与输出之间的函数关系,也就是通过学习,这个黑箱可以逼近任意的函数,理论上,只要数据足够多,神经元数量足够大,神经网络就能学到你需要的东西
激活函数
我们看到,在加权求和之后,我们进行了sigmoid计算,才得到最终的输出,这在逻辑回归中也是这样做的,这个sigmoid函数就是我们所说的激活函数,那么为什么一定要多这一步激活函数呢?激活函数的作用是什么呢?这个问题,可以参考如下知乎的回答,还是解释的蛮清楚的。https://www.zhihu.com/question/22334626/answer/21036590
总结下来就是:激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。我们都知道,有的时候一条直线并不能将数据分类,但是引入非线性的因素就变得可能了。更何况,神经网络中的每一个神经元都是一个非线性的分类过程,将多个非线性的分类组合起来,就是它能逼近任意函数的原因了。
当然激活函数不只有sigmoid函数,还有tanh、softmax、Relu等等,见http://www.cnblogs.com/steven-yang/p/6357775.html
前向传播
接下来我们来看看完整的神经网络计算过程,一个3*3*1的神经网络如下图:

我们知道输入层的输入为x1,x2,x3,以及参数w和b(各边上的权值w以及常数节点的输出值b),我们要计算最后这个网络输出的y是多少,计算过程如下:

这样给定输入,和各参数的值,我们就能得到输出,这个计算过程叫前向传播
反向传播
然而,通常,在我们构建完神经网络后,参数w、b我们都是不知道的,这正是我们要学习获得的参数,而我们有的东西,只有两部分,一是构建好的神经网络(至于如何构建,也就是隐藏层有多少、每层选多少个神经元节点,这些都不是固定的,只能靠实践去探索,通常在特定场景下,输入层和输出层的节点个数是确定的),另一个是我们的训练数据,也就是一堆的(x,y)的样本(x和y都是向量,向量的维度对应了输入层和输出层的节点个数),而我们需要通过这两样已知的东西去求解w和b,这就是神经网络的学习过程。
神经网络的学习方法有很多,我们这里介绍最经典的一种,反向传播BP算法(Back Propagation)。
因为涉及到公式,而markdown写公式实在蛋疼,所以我借助ufldl的讲解来说明吧,实在需要推导的地方,我就手写推导下。
损失函数
首先,我们是利用批量梯度下降的思路去求解各个参数,这跟逻辑回归参数求解的思路一样,那么首先我们需要定义损失函数,损失函数的定义如下:

参数初始化

参数更新

那么关键是如何求导,下面做详细讲解:

看到这里,你肯定跟我开始看一样一脸懵逼,不是要求对w参数和b参数的求导么,这个残差是什么鬼,先不要着急,我们先按他说的理解,这个残差就是代表了这个节点对最终输出值的影响,它其实拿损失函数对这个节点的直接输出(即还没有使用激活函数,只是做了加权求和的输出)进行求导的结果。
上面这个求导过程,首先我们要搞清楚,损失函数是考虑了所有样本的,而这里的计算,我们是先取一个样本计算(因为全部样本的单个结果算出来,整体的也就能算出来了)。
首先,是拿这个样本的输入即x,以及现在的各个参数w、b,从前向后计算出所有神经元节点的输出值。然后计算每一层(不包括输入层)各个节点的残差。而输出层又和隐藏层的残差计算有些微不同,所以先看输出层的残差如何计算,上面图中直接给出了公司,我们来推导一下:

推导过程还是比较简单,我们只要记住,最后的结果是,输出层的激活值与实际值的差乘以该节点未激活值的激活函数倒数的相反数
那么对于隐藏层的残差,又是如何计算呢?看下图(附带推导过程):

需要注意的是,这里推导的时候,是用nl-1层举例,进而得到l层与l+1层之间的关系
这里我们得到了所有节点的残差值,但是并没有得到最初我们想得到的损失函数对w和b参数的导数,下图给出了最终的计算公式:

他的推导过程如下:

注意,我的i和j与上图中颠倒了,因为我认为这里的i是前一层的节点序号,而上图认为i是下一层的节点序号,这不影响。
当然,上面不论是计算残差,还是计算w和b的导数,都是一个一个节点计算,或者一个一个参数计算,其实,我们可以将它转化为矩阵、向量的计算,将上面的计算过程用矩阵-向量法重写,如下:(注意这里还是针对一个样本的过程)

有了一个样本的计算过程,那么我们的整个批量梯度下降学习过程就如下了:

当然,如果你还是没法理解,可以参考下文,下文用一个示例非常清晰地展示了反向传播的计算过程:http://www.cnblogs.com/charlotte77/p/5629865.html
神经网络实战-手写数字识别
最后,我们来进行一次神经网络的实战,实现参考:https://www.zybuluo.com/hanbingtao/note/476663,不过这篇文章中的代码直接跑是跑不通的,我也不知道是因为版本问题还是什么,反正经过我的调整后,用python3.5是能顺利跑出结果的,我调整后的代码在下面贴出。完整代码获取:https://github.com/shadowJF/Neural-Network/tree/master/simple-NN-for-MNIST
任务为识别手写数字,这是神经网络入门比较经典的一个任务,有一个专门的数据集MNIST
该数据集分为训练集和测试集,训练集有60000条数据,包括图片和标签,测试集有10000条数据,包括图片和标签。
我们的任务就是利用训练集训练一个简单的神经网络模型,来对测试集的图片数据进行分类,来判断到底是数字几,最后和标签对比,来得到准确率。
确定神经网络结构
首先,我们需要确定神经网络的结构,第一次实践,就选择一个最简单的三层结构,即只包含一个隐藏层。输入层的神经元个数是确定的为784,为什么呢?因为每个图片数据是28*28像素的图片,因此有784个像素,每个像素对应一个神经元节点。而输出层的神经元节点数为10,这是因为,我们总共有10个数字,0到9,最后输出结果为一个10维向量,每一维对应该图片属于数字几的概率,最后肯定是选择数值最大的那一维对应的数字作为我们的分类结果。
那么层数、输入层节点数、输出层节点数我们都确定了,现在只需要确定隐藏层的节点个数了,有一些经验公式去确定,但最好的方法是自己去实验决定,这里为了简单,我们先随便选一个300个节点好了。
处理数据
首先,我们先处理数据,将数据已向量形式读进来,处理之前,我们得了解MNIST数据的格式,参考如下网页:http://m.blog.csdn.net/sysushui/article/details/53257185
data_handler.py,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import struct
from datetime import datetime
# 数据加载器基类
class Loader(object):
def __init__(self, path, count):
'''
初始化加载器
path: 数据文件路径
count: 文件中的样本个数
'''
self.path = path
self.count = count
def get_file_content(self):
'''
读取文件内容
'''
f = open(self.path, 'rb')
content = f.read()
f.close()
return content
def to_int(self, byte):
'''
将unsigned byte字符转换为整数
似乎content的内容单个读出来已经是int类型了,所以这里不用转换直接返回,可能与python版本有关,我这里用的3.5
'''
return byte
#return struct.unpack('B', byte)[0]
# 图像数据加载器
class ImageLoader(Loader):
def get_picture(self, content, index):
'''
内部函数,从文件中获取图像
'''
start = index * 28 * 28 + 16
picture = []
for i in range(28):
picture.append([])
for j in range(28):
picture[i].append(
float(self.to_int(content[start + i * 28 + j]))/255)
#重要!这里一定要将图片像素数值归一化
return picture
def get_one_sample(self, picture):
'''
内部函数,将图像转化为样本的输入向量
'''
sample = []
for i in range(28):
for j in range(28):
sample.append(picture[i][j])
return sample
def load(self):
'''
加载数据文件,获得全部样本的输入向量
'''
content = self.get_file_content()
data_set = []
for index in range(self.count):
data_set.append(
self.get_one_sample(
self.get_picture(content, index)))
return data_set
# 标签数据加载器
class LabelLoader(Loader):
def load(self):
'''
加载数据文件,获得全部样本的标签向量
'''
content = self.get_file_content()
labels = []
for index in range(self.count):
labels.append(self.norm(content[index + 8]))
return labels
def norm(self, label):
'''
内部函数,将一个值转换为10维标签向量
'''
label_vec = []
label_value = self.to_int(label)
for i in range(10):
if i == label_value:
label_vec.append(0.9)
else:
label_vec.append(0.1)
return label_vec
def get_training_data_set():
'''
获得训练数据集
'''
image_loader = ImageLoader('train-images.idx3-ubyte', 60000)
label_loader = LabelLoader('train-labels.idx1-ubyte', 60000)
return image_loader.load(), label_loader.load()
def get_test_data_set():
'''
获得测试数据集
'''
image_loader = ImageLoader('t10k-images.idx3-ubyte', 10000)
label_loader = LabelLoader('t10k-labels.idx1-ubyte', 10000)
return image_loader.load(), label_loader.load()
if __name__ == "__main__":
train_data,train_label = get_training_data_set()
test_data,test_label = get_test_data_set()
print("训练数据总共有:%d条,测试数据总共有:%d条" % (len(train_data),len(test_data)))
print("样例训练数据如下:")
print(train_data[0])
print(train_label[0])
测试输出如下,每个训练样本的图片是一个784维的数据,标注是一个10维的数据。
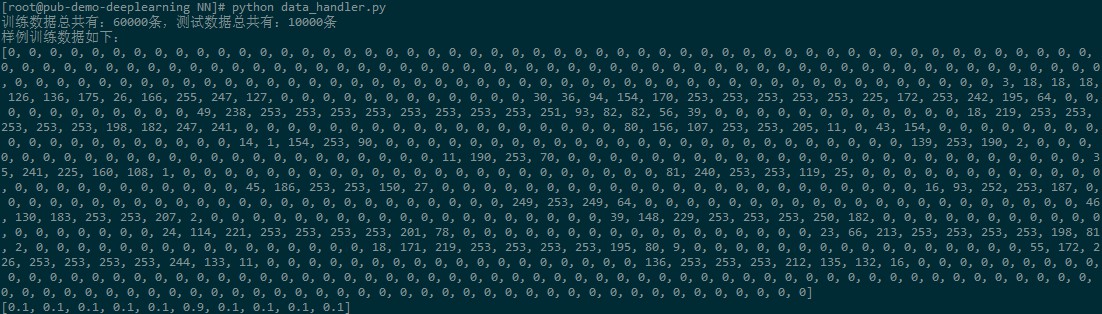
但是,注意上面ImageLoader的load方法中,我添加了一条重要的注释,就是,我们从原始的MNIST数据集中读出来的像素数据,每一个像素是0-255之间的一个数,如果我们不做归一化,那么读出来的结果就如上所示,但是我们用这样的数据去做训练,是无法得到有效的模型的,这也是我之前训练一直不成功的原因,训练几十轮发现错误率还是在80%左右。我当时纠结了好久,觉得是不是模型写错了,找了各种原因。后来看TensorFLow的MNIST识别文档时,发现他们使用的MNIST数据集的像素数值都是在0-1之间的,而我之前看到过一篇文章,说为什么要将神经网络的输入归一化,是因为如果不归一化,那么如果数据很大,那么每个节点的输出有可能都是落在一个很大的区间(这时还未激活),而激活之后,这些神经节点的输出就都是1了,这样就没有什么区分性了。所以,我们这里将像素值归一化。后面的训练效果就很好很好了,基本上十几轮训练就能达到98%以上的准确率了。
神经网络实现
接着,我们需要实现神经网络的核心代码。首先,我们实现一个全连接层,他接收上一层的输入,并计算下一层的输出(前向传播),同时也能根据下一层的残差,来计算上一层的残差(反向传播),代码如下:
connector.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
import numpy as np
# 全连接层实现类
class FullConnectedLayer(object):
def __init__(self, input_size, output_size,
activator):
'''
构造函数
input_size: 本层输入向量的维度
output_size: 本层输出向量的维度
activator: 激活函数
'''
self.input_size = input_size
self.output_size = output_size
self.activator = activator
# 权重数组W,output_size为行,input_size为列的矩阵,数值在-0.1到0.1之间随机分布
self.W = np.random.uniform(-0.1, 0.1,
(output_size, input_size))
# 偏置项b,一个outpu_size维的向量
self.b = np.zeros(output_size)
# 输出向量
self.output = np.zeros(output_size)
def forward(self, input_array):
'''
前向计算
input_array: 输入向量,维度必须等于input_size
'''
# 式2
self.input = input_array
self.output = self.activator.forward(
np.dot(self.W, input_array) + self.b)
#print("w:")
#print(self.W)
#print("b:")
#print(self.b)
def backward(self, delta_array):
'''
反向计算W和b的梯度
delta_array: 从上一层传递过来的误差项
'''
# 式8
self.delta = self.activator.backward(self.input) * np.dot(
self.W.T, delta_array)
self.W_grad = np.dot(delta_array.reshape(-1,1), self.input.reshape(-1,1).T)
#这里用reshape,是因为delta_array和input都是一个向量,向量直接相乘得到的还是一个向量而不是我们需要的矩阵,所以这里做一次reshape,将向量转换为矩阵,通过矩阵乘法得到一个矩阵
self.b_grad = delta_array
#print("w.T:")
#print(self.W.T)
#print("delta_array:")
#print(delta_array)
#print("delta:")
#print(self.delta)
#print("W_grad:")
#print(self.W_grad)
def update(self, learning_rate):
'''
使用梯度下降算法更新权重
'''
self.W += learning_rate * self.W_grad
self.b += learning_rate * self.b_grad
连接层的实现还是比较简单的,如果我们有三层神经网络,那么就应该有两层全连接层,即从输出层到隐藏层,以及从隐藏层到输出层的两个连接层。每个连接层,需要三个构造参数,上一层的神经元个数即input_size,下一层的神经元个数即output_size,以及一个激活函数activator。同时初始化权重w和偏置项b
对于前向计算,比较好理解,用权重矩阵与输入向量相乘再加上偏置项,最后利用激活函数激活,即得到输出向量。参考公式如下:
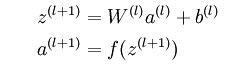
对于反向计算w和b的梯度,可能初学者不好理解,没事,翻翻前面对反向传播算法的介绍,对比公式如下:

上面的backward算法,接收一个delta_array作为输入,这就是下一层传过来的残差矩阵,与本层的权重矩阵的逆相乘再乘上本层输入的激活函数的导数
本层的残差计算完之后是为前一层的梯度计算服务的,而本层的w和b的梯度是利用上一层的残差来计算的。
最后是一个更新权重的函数update,我们知道一般都是用原参数减去梯度,但这里是加上梯度,这是因为我们后面有个地方使用了相反数,后面再说。
接着我们看下激活函数的实现,激活函数,我们选择的是sigmoid函数,forward方法为计算sigmoid函数值,backward方法为计算sigmoid方法的导数
activator.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import numpy as np
# Sigmoid激活函数类
class SigmoidActivator(object):
def forward(self, weighted_input):
l = []
for num in weighted_input:
if num <= -700:
value = 0
else:
value = 1.0 / (1.0 + np.exp(-num))
l.append(value)
return np.array(l)
def backward(self, output):
return output * (1 - output)
这里也是我调整的地方,这里如果不对num的大小做判断,直接使用sigmoid方法来计算函数值会报overflow的错误,这是因为np.exp()方法传进去的参数如果过大,就会报overflow,但是我们知道在num过小的时候,sigmoid函数的输出肯定是一个无线接近于0的值,所以这里我们直接返回0,而不让他报overflow的错误。
最后,我们再实现神经网络类:
network.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
from connector import *
from activator import *
# 神经网络类
class Network(object):
def __init__(self, layers):
'''
构造函数
'''
self.layers = []
for i in range(len(layers) - 1):
self.layers.append(
FullConnectedLayer(
layers[i], layers[i+1],
SigmoidActivator()
)
)
def predict(self, sample):
'''
使用神经网络实现预测
sample: 输入样本
'''
output = np.array(sample) #这里我们先将输入由list转为np中的array,因为只有array才能直接参与计算,如果直接用list与一个数相加会报错
for layer in self.layers:
layer.forward(output)
output = layer.output
#print("layer output:")
#print(output)
return output
def train(self, labels, data_set, rate, epoch):
'''
训练函数
labels: 样本标签
data_set: 输入样本
rate: 学习速率
epoch: 训练轮数
'''
for i in range(epoch):
for d in range(len(data_set)):
if d % 1000 == 0:
print("处理到第%d个样本:" % (d))
self.train_one_sample(labels[d],
data_set[d], rate)
def train_one_sample(self, label, sample, rate):
#print("one sample predict:")
#print("label:")
#print(label)
#print("data:")
#print(sample)
self.predict(sample)
#print("calc_gradient:")
self.calc_gradient(label)
#print("update_weight")
self.update_weight(rate)
def calc_gradient(self, label):
delta = self.layers[-1].activator.backward(
self.layers[-1].output
) * (label - self.layers[-1].output)
for layer in self.layers[::-1]:
layer.backward(delta)
delta = layer.delta
return delta
def update_weight(self, rate):
for layer in self.layers:
layer.update(rate)
需要注意的是,我们这里的实现并不是用批量随机梯度下降算法,而是随机梯度下降算法,我们来看train方法,epoch是迭代次数,在每一轮迭代中,我们依次取每一个样本,对参数进行一次更新,来看看train_one_sample里面都做了什么,首先是执行self.predict(sample),这是在进行前向传播过程,即计算出所有节点的激活值,这里的sample就是样本数据的输入,在我们这里是一个784维的数据。
接着执行self.calc_gradient(label)的操作,这一步是计算各参数的梯度,在该方法里,首先,我们计算了输出层的残差,参考如下公式:

但是,心细的你发现了没有,代码中少了个负号,这也是我们之前说的那个更新参数的地方为什么是加上梯度而不是减去梯度的原因了。
得到输出层的残差后,我们就可以从后向前,依次执行每一层的backward方法了,之前也提到了在连接层的backward方法里,我们首先计算出本层的残差,然后计算了本层参数w和b的梯度
当所有梯度都计算出来后,执行了self.update_weight(rate),即对所有的参数进行更新的操作
这样对单个样本的参数更新就完成了,对所有样本都处理一次后,一次迭代就算完成了。
那么最后,实现我们的训练策略:每训练10轮,评估一次准确率,当准确率开始下降时终止训练。下面是代码实现:
train.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
from network import *
from data_handler import *
from datetime import datetime
def get_result(vec):
max_value_index = 0
max_value = 0
for i in range(len(vec)):
if vec[i] > max_value:
max_value = vec[i]
max_value_index = i
return max_value_index
def evaluate(network, test_data_set, test_labels):
error = 0
total = len(test_data_set)
for i in range(total):
label = get_result(test_labels[i])
predict = get_result(network.predict(test_data_set[i]))
if label != predict:
error += 1
return float(error) / float(total)
def train_and_evaluate():
last_error_ratio = 1.0
epoch = 0
train_data_set, train_labels = get_training_data_set()
test_data_set, test_labels = get_test_data_set()
print("数据加载完毕")
network = Network([784, 300, 10])
while True:
epoch += 1
print("开始第%d轮训练" % (epoch))
network.train(train_labels, train_data_set, 0.3, 1)
print('%s epoch %d finished' % (datetime.now(), epoch))
if epoch % 1 == 0:
error_ratio = evaluate(network, test_data_set, test_labels)
print ('%s after epoch %d, error ratio is %f' % (datetime.now(), epoch, error_ratio))
if error_ratio > last_error_ratio:
break
else:
last_error_ratio = error_ratio
if __name__ == '__main__':
train_and_evaluate()
其中get_result()方法是根据输出的10维向量来决定数字被识别为哪个数字,当然就是哪一维上的数值最大那么这个图片就被识别为哪一个数字。
evaluate()方法为错误率评估,根据测试集的识别结果计算,出错个数除以整个测试集的个数。
我们构建了一个784*300*10的三层神经网络,每训练1轮输出一次错误率,最后发现在10几轮的时候,就差不多收敛了。错误率在0.019左右。效果还是蛮好了。
参考资料
https://www.tensorflow.org/get_started/mnist/beginners
http://m.blog.csdn.net/sysushui/article/details/53257185
https://www.zybuluo.com/hanbingtao/note/476663
http://ufldl.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95
http://www.cnblogs.com/charlotte77/p/5629865.html